由于Pydumpling本身的dump文件中保存了程序异常退出时的调用栈信息,我们可以考虑将调用栈可视化。
我要认领
1 个赞

看起来样式上应该没问题,主要是界面上要展示哪些有效信息。可以直接提PR,我们一起看看
已提交 PR
FakeTraceack, FakeFrame 和FakeCode中展示的字段(在serialize 方法中):
class FakeTraceback(FakeType):
def __init__(self, traceback=None):
# 指向当前层级的执行 帧对象
self.tb_frame = FakeFrame(
traceback.tb_frame) if traceback and traceback.tb_frame else None
# 异常发生所在的行号
self.tb_lineno = traceback.tb_lineno if traceback else None
# 下一个 traceback, 没有则为 `None`
self.tb_next = FakeTraceback(
traceback.tb_next) if traceback and traceback.tb_next else None
# 表示 `精确指令`
self.tb_lasti = traceback.tb_lasti if traceback else 0
def serialize(self):
return {
'tb_frame': self.tb_frame.serialize() if self.tb_frame else None,
'tb_lineno': self.tb_lineno,
'tb_next': self.tb_next.serialize() if self.tb_next else None,
}
class FakeFrame(FakeType):
def __init__(self, frame):
self.f_code = FakeCode(frame.f_code) # 改帧中正在被执行的 代码对象
self.f_locals = self._convert_dict(frame.f_locals) # 改帧包含的 局部变量 的映射字典
if "self" in frame.f_locals:
self.f_locals["self"] = self._convert_obj(frame.f_locals["self"])
self.f_globals = self._convert_dict(frame.f_globals) # 改帧包含的 全局变量 的映射字典
self.f_lineno = frame.f_lineno # 该帧的当前行号 -- 在这里写入从一个跟踪函数内部跳转到的给定行(仅用于最底层的帧)
self.f_back = FakeFrame(frame.f_back) if frame.f_back else None # 指向前一个帧(对于调用方而言),如果是最底部的栈帧则为 None
self.f_lasti = frame.f_lasti # 帧对象的 精确指令
self.f_builtins = frame.f_builtins # 内置对象
def serialize(self):
return {
'f_code': self.f_code.serialize(),
'f_lineno': self.f_lineno,
}
class FakeCode(FakeType):
def __init__(self, code):
self.co_filename = os.path.abspath(code.co_filename) # 代码所在的文件绝对路径
self.co_name = code.co_name # 表示函数或方法的名称
self.co_argcount = code.co_argcount # 表示函数的位置参数数量,包括位置参数和有默认值的参数。
self.co_consts = tuple(FakeCode(c) if hasattr(
c, "co_filename") else c for c in code.co_consts) # 包含函数字节码中使用的字面量常量的元组。
self.co_firstlineno = code.co_firstlineno # 表示函数定义所在文件中的行号。
self.co_lnotab = code.co_lnotab # 一个字符串,它映射了字节码偏移量与源代码行号之间的关系。
self.co_varnames = code.co_varnames # 一个元组,包含了函数内所有局部变量的名称。它是按顺序列出的,形参排在前面,局部变量排在后面。
self.co_flags = code.co_flags # 一个整数,它对字节码解释器的各种标志进行了编码。
self.co_code = code.co_code # 一个字符串,表示函数中的字节码指令序列。
self._co_lines = list(code.co_lines()) if hasattr(
code, "co_lines") else [] # 返回一个产生有关 bytecode 的连续范围的信息的迭代器。
if hasattr(code, "co_kwonlyargcount"):
self.co_kwonlyargcount = code.co_kwonlyargcount # 函数中仅限关键字参数的数量。
if hasattr(code, "co_positions"):
self.co_positions = code.co_positions # 返回一个包含代码对象中每条 bytecode 指令的源代码位置的可迭代对象。
def co_lines(self):
return iter(self._co_lines)
def serialize(self):
return {
'co_filename': self.co_filename,
'co_name': self.co_name,
}
很多属性都是关于参数(形参,围位置参数等)数量,bytecode相关的,所以没有出现在序列化那部分。
通过序列化之后,同归递归的方式提取所有的 tb_frame, 然后使用 visjs/vis-network: ![]() Display dynamic, automatically organised, customizable network views.
Display dynamic, automatically organised, customizable network views.
进行可视化。
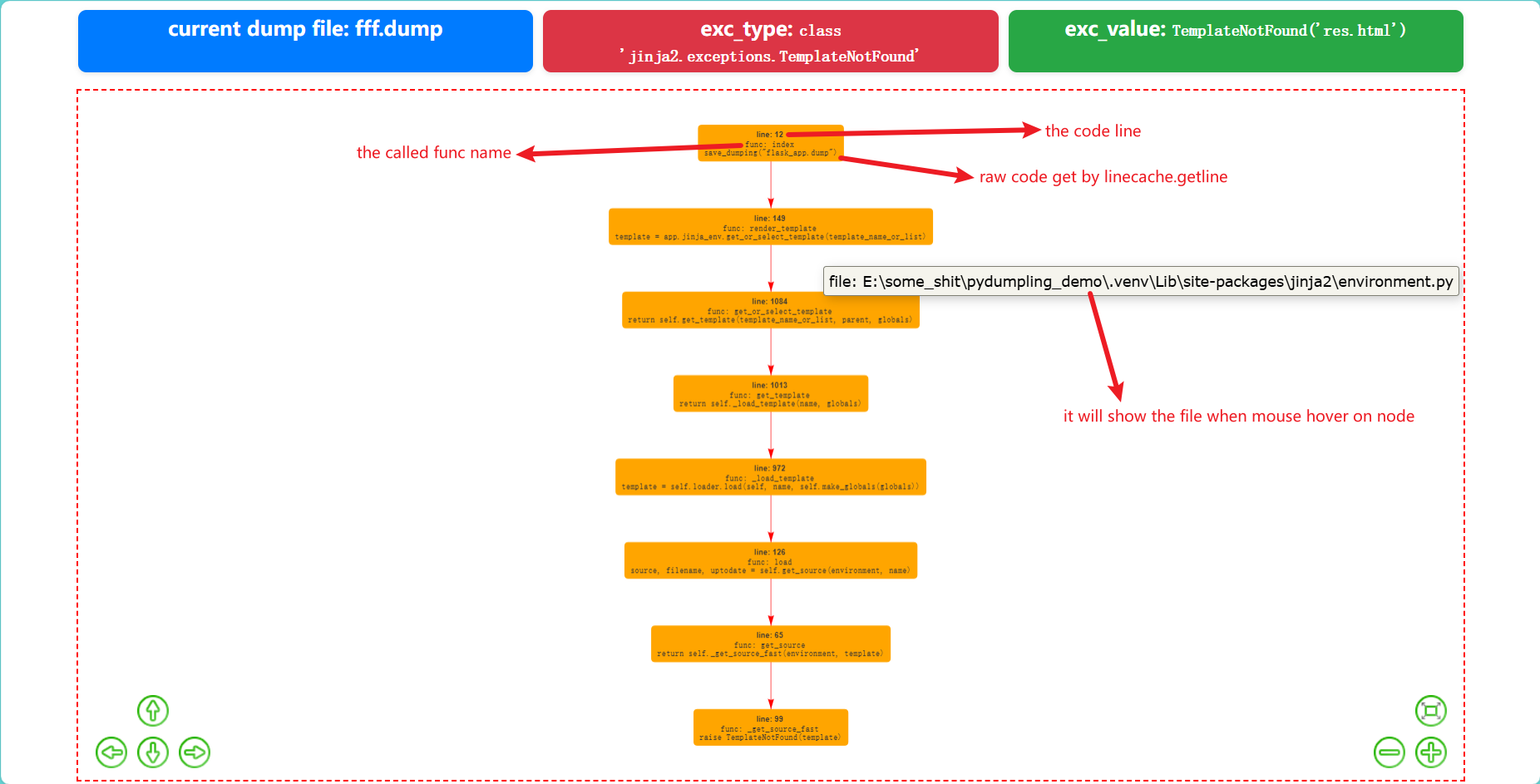
上图是一些说明。
2 个赞